
Scaling Behavior Cloning Improves Causal Reasoning: An Open Model for Real-Time Video Game Playing
Open Pixel2Play (P2P)

💻 code available at https://github.com/elefant-ai/open-p2p
🤗 data available at: https://huggingface.co/datasets/elefantai/p2p-full-data
🎥 videos available at https://elefant-ai.github.io/open-p2p/
(a collection of games the model can play at a reasonable level right now)
We introduce Pixels2Play (P2P), an open-source generalist agent designed for real-time control across diverse 3D video games on consumer-grade GPUs. Built on an efficient, decoder-only transformer architecture that predicts keyboard and mouse actions from raw pixel inputs , the model is trained on a massive new dataset of over 8,300 hours of high-quality, text-annotated human gameplay. Beyond achieving human-level competence in commercial environments like DOOM and Roblox , we systematically investigate the scaling laws of behavior cloning, demonstrating that increasing model and data scale significantly improves causal reasoning and mitigates the "causal confusion" often inherent in imitation learning. To accelerate research in generalist game AI, we are releasing the full training recipe, model checkpoints, and our extensive gameplay dataset under an open license.
🎮 Now watch our model plays with a real human player on Roblox Rival!
Training Dataset:

We release a large-scale dataset of high-quality human gameplay spanning diverse 3D video games including FPS (DOOM, Quake, Call of Duty, etc.), racing (Need for Speed, etc.), Roblox games, and other popular video games. All gameplay is recorded at 20 FPS by experienced players. Each frame is annotated with keyboard and mouse actions, and text instructions are provided when available.
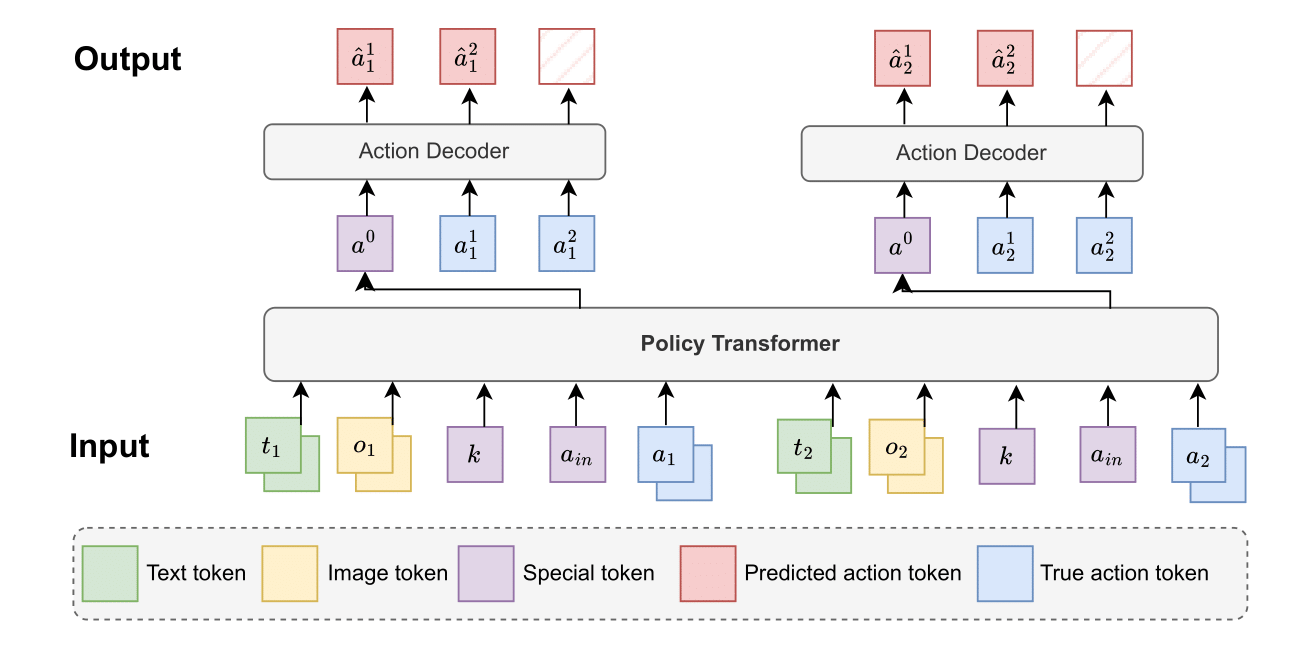
Policy Model:
Our model, Pixels2Play (P2P), is an action policy that takes visual observations and optional text instructions as input to output keyboard and mouse actions. The model is designed for high-speed, real-time inference (20 Hz) on consumer-level GPUs. The architecture is composed of a backbone transformer and a lightweight action decoder. The backbone transformer is responsible for sophisticated spatio-temporal reasoning between the visual inputs, text inputs, and the output action. The action decoder then predicts the final mouse and keyboard actions based on a compressed action prediction token generated by the backbone. This structure accelerates inference speed by a factor of 5 while maintaining high prediction accuracy.
The model employs an EfficientNet-based image encoder to compress visual observations into compact visual tokens, and a Gemma text encoder to compress text instructions into compact text tokens. One ground truth action consists of eight tokens: four representing simultaneous keyboard actions, two representing mouse movement on the x and y axes, and two representing mouse button actions. These ground truth action tokens are provided as input so the model can leverage prior actions to perform more like a human. To maintain the causality of the model, we designed a customized attention mask to ensure that the action prediction token only attends to prior ground truth action tokens.
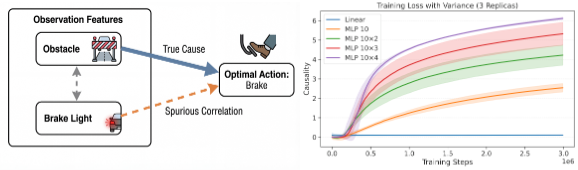
Causality and Scaling:
1. Causality in a Controlled Toy Environment
In this controlled setup, an optimal linear policy exists that can solve the task. However, we found that standard gradient descent fails to find this solution in linear models. By increasing network depth and adding non-linearity, the optimization process is better able to overcome spurious correlations. These results suggest that increased capacity and depth do not just improve performance—they actively facilitate the discovery of true causal signals during training.
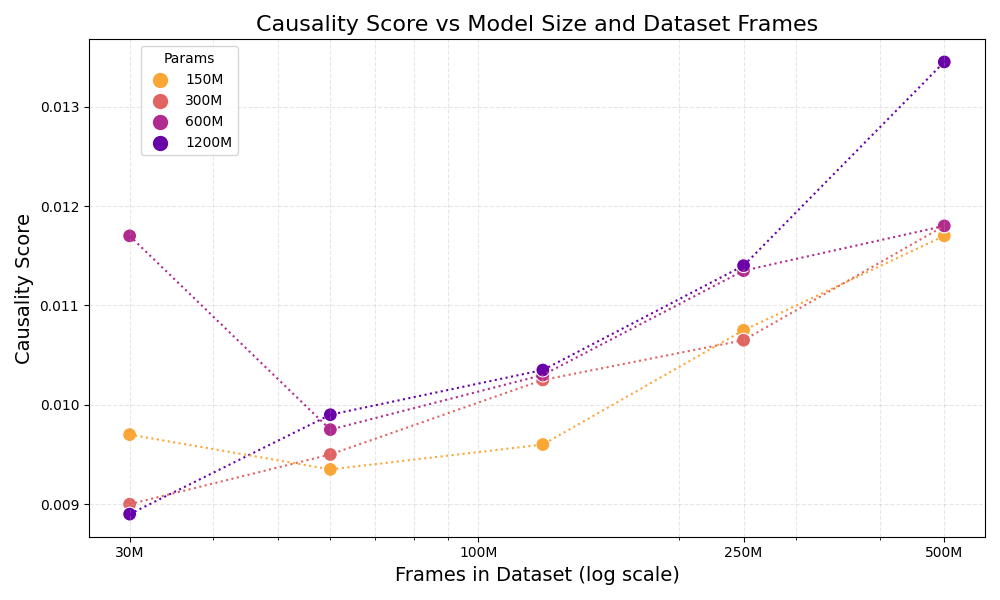
2. Empirical Evidence in Large-Scale Environments
In our full-scale experiments, we observed an empirical phenomenon that mirrors the findings from the toy example.
We found that increasing model parameters and dataset volume naturally mitigates causal confusion. Even without explicit architectural interventions to address causality, larger models demonstrate a superior ability to distinguish between essential environmental cues and non-causal distractors. This suggests that scale provides a practical, robust solution to the causal challenges inherent in generalist gaming agents.
Very nice and timely work.
Where can one read in more details about your toy experiment setup and the large scale one? Like how did you define the causality score and why it has been concluded that causal confusion reduces by depth and more data? Do you have some scaling laws on that?